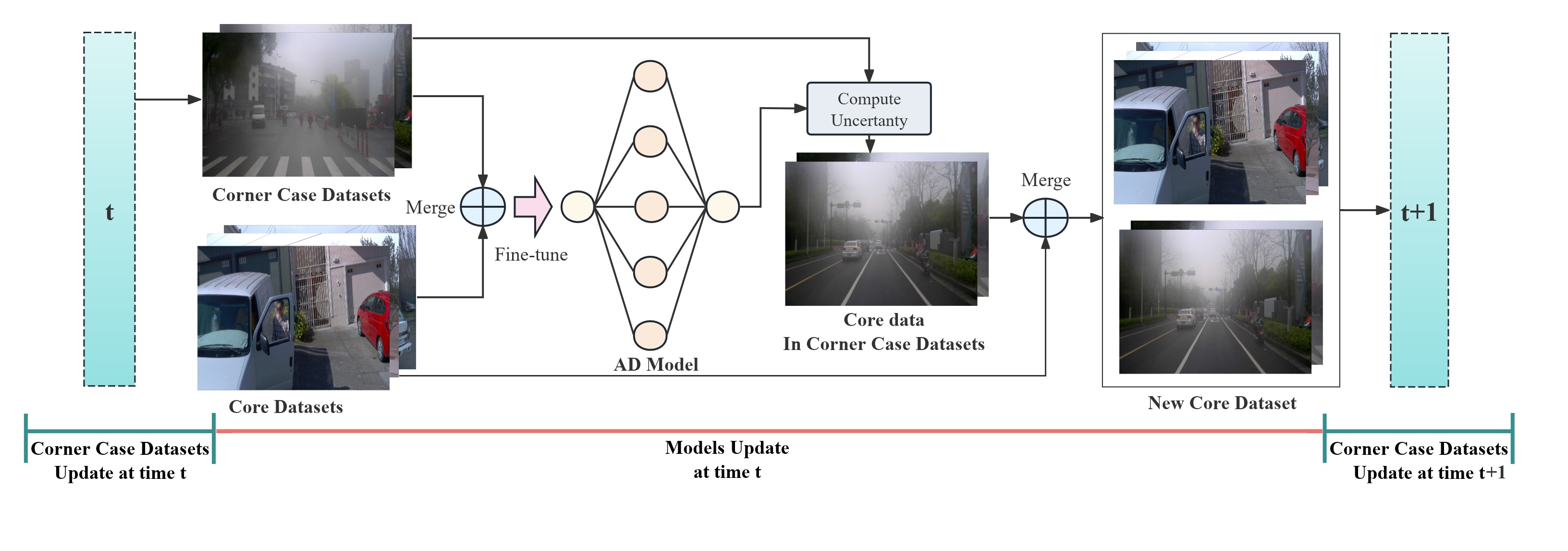
Continual Update of the AD Model under the VLM-C4L Framework

With the widespread adoption and deployment of autonomous driving, handling complex environments has become an unavoidable challenge. Due to the scarcity and diversity of extreme scenario datasets, current autonomous driving models struggle to effectively manage corner cases. This limitation poses a significant safety risk—according to the National Highway Traffic Safety Administration (NHTSA), autonomous vehicle systems have been involved in hundreds of reported crashes annually in the United States, some of which occurred corner case like sun glare and foggy, which caused a few fatal accident~\cite{tesla2024}. Furthermore, in order to consistently maintain a robust and reliable autonomous driving system, it is essential for models not only to perform well on routine scenarios but also to adapt to newly emerging scenarios—especially those corner cases that deviate from the norm. This requires a learning mechanism that incrementally integrates new knowledge without degrading previously acquired capabilities. However, to the best of our knowledge, no existing continual learning methods have been proposed to ensure consistent and scalable corner case learning in autonomous driving. To address these limitations, we proposal VLM-C4L, a continual learning framework that introduce Vision-Language Models (VLMs) to dynamically optimize and enhance corner case datasets, and VLM-C4L combines VLM-guided high-quality data extraction with a core data replay strategy, enabling the model to incrementally learn from diverse corner cases while preserving performance on previously routine scenarios, thus ensuring long-term stability and adaptability in real-world autonomous driving. We evaluate VLM-C4L on large-scale real-world autonomous driving datasets, including Waymo and the corner case dataset CODA. To assess the effectiveness of our approach, we employ Sparse R-CNN, the strongest model in the CODA benchmark, and Cascade-DETR, a widely recognized model. Experimental results demonstrate that VLM-C4L significantly enhances object detection performance in complex traffic scenarios, such as light pollution and foggy conditions, with AP and AR scores nearly matching those in regular scenarios.
| Methods | WAYMO | Light Pollution | Foggy | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AP | AP50 | AP75 | AR1 | AR10 | AR100 | |
| Sparse R-CNN | 36.4 | 45.9 | 14.6 | 25.5 | 15.1 | 12.0 | 26.9 | 30.2 | 16.7 | 28.0 | 17.8 | 11.9 | 27.3 | 29.8 |
| Sparse R-CNN + VLM-C4L (ours) | 34.7 | 45.1 | 20.2 | 42.4 | 31.4 | 19.7 | 52.3 | 30.7 | 36.4 | 46.5 | 33.9 | 18.0 | 41.3 | 33.5 |
| Cascade-DETR | 35.5 | 48.1 | 18.8 | 33.0 | 18.0 | 13.0 | 41.0 | 29.4 | 35.0 | 38.0 | 18.4 | 12.2 | 28.7 | 33.5 |
| Cascade-DETR + VLM-C4L (ours) | 33.3 | 46.5 | 30.4 | 48.3 | 31.2 | 20.7 | 49.6 | 31.1 | 24.9 | 40.2 | 25.4 | 16.9 | 39.5 | 40.8 |
| Methods | WAYMO | Light Pollution | Foggy | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AP | AP50 | AP75 | AR1 | AR10 | AR100 | |
| Sparse R-CNN + Random | 34.6 | 43.8 | 20.4 | 41.0 | 15.1 | 10.0 | 35.9 | 39.2 | 24.7 | 25.1 | 14.1 | 10.2 | 30.4 | 31.4 |
| Sparse R-CNN + VLM-DB | 34.9 | 44.9 | 22.9 | 39.9 | 24.1 | 14.3 | 45.6 | 35.5 | 33.6 | 33.7 | 26.2 | 14.8 | 36.0 | 36.1 |
| Sparse R-CNN + Random + Data Aug | 35.1 | 45.2 | 22.6 | 42.2 | 19.8 | 13.5 | 42.9 | 32.0 | 31.2 | 35.7 | 17.6 | 14.1 | 31.8 | 35.3 |
| Sparse R-CNN + VLM-C4L (ours) | 33.7 | 46.1 | 31.5 | 52.4 | 34.1 | 20.1 | 54.1 | 37.4 | 29.5 | 41.1 | 32.2 | 17.6 | 41.3 | 41.5 |
| Cascade-DETR + Random | 34.5 | 47.5 | 17.5 | 30.4 | 14.2 | 9.7 | 33.6 | 33.2 | 27.7 | 29.6 | 18.4 | 10.0 | 30.1 | 34.4 |
| Cascade-DETR + VLM-DB | 35.0 | 48.1 | 21.7 | 40.2 | 17.5 | 12.7 | 42.9 | 36.7 | 27.2 | 32.2 | 18.5 | 12.2 | 33.3 | 35.8 |
| Cascade-DETR + Random + Data Aug | 35.1 | 48.4 | 21.8 | 38.2 | 17.0 | 12.0 | 40.5 | 33.6 | 28.0 | 30.5 | 21.4 | 12.3 | 35.3 | 33.9 |
| Cascade-DETR + VLM-C4L (ours) | 33.3 | 46.5 | 30.4 | 48.3 | 31.2 | 20.7 | 49.6 | 54.1 | 24.9 | 40.2 | 25.4 | 16.9 | 39.5 | 40.8 |
| Conf. Ratios | WAYMO | Light Pollution | Fog | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AP | AP50 | AP75 | AR1 | AR10 | AR100 | |
| τ = 0.2 | 34.6 | 44.0 | 24.5 | 41.3 | 26.6 | 18.1 | 40.0 | 43.8 | 23.8 | 37.3 | 26.5 | 14.9 | 34.0 | 36.7 |
| τ = 0.4 | 34.9 | 44.9 | 23.9 | 39.9 | 24.4 | 17.2 | 39.8 | 43.3 | 23.8 | 37.3 | 26.2 | 14.8 | 34.0 | 36.4 |
| τ = 0.6 | 34.2 | 43.4 | 23.5 | 39.5 | 24.6 | 16.3 | 38.4 | 41.8 | 23.0 | 35.9 | 25.4 | 14.7 | 32.2 | 35.4 |
| Core Data | WAYMO | Light Pollution | Fog | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AR | AP | AP50 | AP75 | AR1 | AR10 | AR100 | AP | AP50 | AP75 | AR1 | AR10 | AR100 | |
| Dcore(1st) = 3000 | 34.6 | 43.8 | 26.8 | 43.9 | 29.1 | 18.3 | 41.8 | 45.4 | 24.3 | 37.8 | 26.8 | 15.1 | 35.3 | 38.0 |
| Dcore(1st) = 10000 | 34.9 | 44.9 | 22.9 | 39.9 | 24.4 | 17.2 | 39.8 | 43.3 | 23.8 | 37.4 | 26.2 | 14.8 | 34.0 | 36.4 |
| Dcore(1st) = 20000 | 35.4 | 44.9 | 19.1 | 32.9 | 19.7 | 15.8 | 33.8 | 36.4 | 20.7 | 33.8 | 22.5 | 13.8 | 31.4 | 33.5 |
BibTex Code Here